CVG
Proyecto realizado para la asignatura Cloud y Big Data impartida en la Facultad de Informática de la Universidad Complutense de Madrid durante el primer cuatrimestre del curso 2017-2018.
This project is maintained by Athoka
Calculate Videogames Grade
Calculate Videogames Grade es un predictor del éxito de un videojuego.
Su misión es predecir la nota que va a obtener un videojuego en función de determinadas características proporcionadas por el usuario.

La aplicación se alimenta con datos históricos de ventas y calificaciones de dos medios especializados. Estos datos son procesados para adaptarlos a un formato común, y mediante un análisis estadístico, cruzando con el valor de las variables proporcionadas por el usuario, se genera una calificación que se devuelve al usuario.
Datos
Los datos empleados en la obtención de estádisticas han sido extraídos de los siguientes archivos CSV: IGN y Metacrític
El fichero de IGN contiene los siguientes datos de 18.625 videojuegos:
- ID.
- Nota en palabra.
- Título.
- URL en IGN.
- Plataforma.
- Nota según IGN.
- Género.
- Si se recomienda el juego o no.
- Año de publicación.
- Mes de publicación.
- Día de publicación.
Los datos que nos importan de este fichero son: la plataforma, la nota, el género y el año y mes de publicación. Nos hemos quedado con sólo estas columnas en un nuevo CSV.
El fichero de Metacrític contiene los siguientes datos de 16.719 videojuegos:
- Nombre.
- Plataforma.
- Año de lanzamiento.
- Género.
- Compañía.
- Ventas en América.
- Ventas en Europa.
- Ventas en Japón.
- Ventas en otros sitios.
- Ventas totales.
- Nota de los críticos.
- Nota de los usuarios.
- Número de usuarios que ha puntuado.
- Estudio de desarrollo.
- Rating.
Al igual que con el fichero de IGN, hemos creado uno nuevo para guardar los datos que nos interesan: plataforma, año de lanzamiento, género, compañía, ventas totales y nota tanto de críticos como de usuarios.
Los dos ficheros fueron parseados para poder ser tratados de forma más sencilla en Spark, no hay cambios sustanciales en los datos.
Diseño
Todo el proyecto está desarrollado en Python, ya que nos parece un lenguaje sencillo a la vez que potente y que permite una buena integración de Spark.
La parte más importante del código es el fichero patrons.py que contiene las funcionalidades Spark: leer CSVs y convertirlos en RDDs en los que buscará los juegos que encajen en las categorías especificadas, agruparlos y calcular su media.
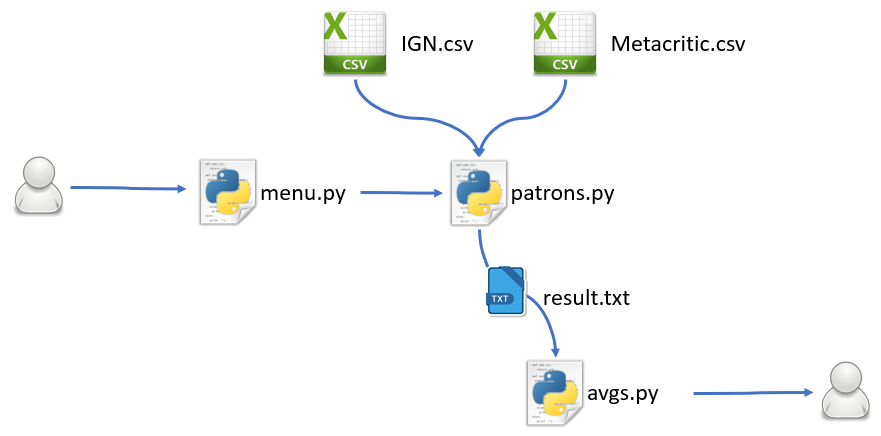
El flujo de uso de la aplicación empieza con un menú menu.py en el que se le pide al usuario que introduzca los datos sobre los que se van a realizar los cálculos.
def get_data(op):
platforms = ["PS4","XOne","WiiU","PSV", "3DS", "PC", "Android"] # the ones used on this moment
correct = False
while correct is False:
platform = raw_input("Platform:")
if platform in platforms:
correct = True
genre = raw_input("Genre:")
dev = raw_input("Developer:")
month = int(raw_input("Month of release (1-12):"))
if month < 1 or month > 12:
correct = False
print("Wrong month!")
else:
correct = True
else:
print("Wrong platform, correct ones are: " + str(platforms))
# Write down the data on a file which is going to be read later by the main program.
file = open("data.txt", "w")
file.write(str(op) + "," + platform + "," + genre + "," + dev + "," + str(month) + "\n")
file.close()
Estos datos se le pasan a patrons.py que utilizando los datos históricos disponibles realiza el análisis estadístico de la entrada. El resultado final se guarda en un fichero result.txt
def developer_avg(metacriticData,sc,developer):
#Do the statisticts related to the given developer
# Search in Metacritic CSV
developerMetacritic = metacriticData.filter(lambda line: developer in line).map(lambda line: (line[3],line[5],line[6]))
if developerMetacritic.isEmpty() is False:
developerMCritics = developerMetacritic.map(lambda line: (line[1])).reduce(lambda x,y: x+y)
developerMUsers = developerMetacritic.map(lambda line: (line[2])).reduce(lambda x,y: x+y)
developerMCount = developerMetacritic.count()
else:
developerMCritics = 0
developerMUsers = 0
developerMCount = 0
#Calculate averega grade
avgs_list,avg = average(developerMCritics,developerMUsers,0,developerMCount,0)
result = sc.parallelize(avgs_list,1)
result.saveAsTextFile("developers.txt")
return avg
Por último el fichero avgs.py muestra la calificación final de los datos proporcionados
categories = ["Platform: ", "Genre: ", "Developer: ", "Month of release: ", "Expected grade: "]
categories2 = ["Platform: ", "Genre: ", "Developer: ", "Expected sales: "]
file_name = sys.argv[1]
file = open(file_name)
option = file.readline()
if int(option) == 3:
result = file.readline()
print("The average is: " + result)
elif int(option) == 1:
for i in range(5):
avg = file.readline()
avg = avg.rstrip("\n")
print(categories[i] + avg)
avg = int(avg)
if avg <= 100 and avg >= 90:
print("EXCELLENT!")
elif avg < 90 and avg >= 70:
print("GREAT")
elif avg < 70 and avg >= 50:
print("GOOD")
else:
print("SORRY :(")
elif int(option) == 2:
for i in range(4):
avg = file.readline()
avg = avg.rstrip("\n")
print(categories2[i] + avg)
file.close()
Infraestructura
Actualmente la aplicación esta diseñada para ser desplegada en un único nodo de hadoop con posibilidad de realizar paralelismo de tareas tal como se muestra a continuación.
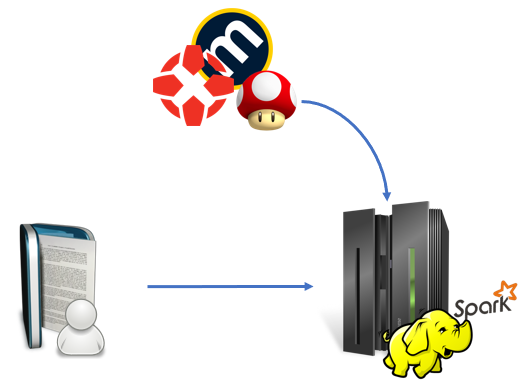
Este despliegue nos permite una escalabilidad horizontal utilizando más nodos con hadoop de forma que sea posible servir las peticiones entrantes y adaptarse a la demanda
Uso de la aplicación
La interacción del usuario con el programa se produce gracias al un script en Bash que permite integrar todos los ficheros comentados en el apartado de diseño. Lo primero que ocurre es que se le muestra al usuario un menú mostrándole las posibles opciones que le ofrece nuestra aplicación.
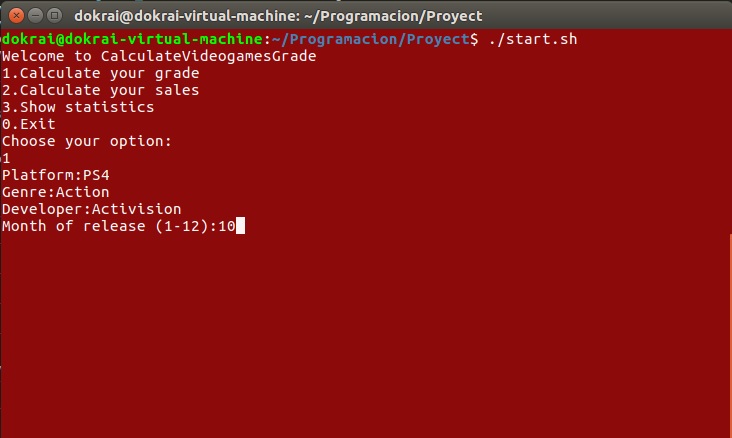
La primera opción es la predicción de notas. Tras seleccionar esta opción se le pedirá al usuario que introduzca por consola los datos sobre su videojuego: plataforma, género, desarrolladora y mes de lanzamiento. Estos datos se pasarán al programa principal para hayar las medias correspondientes a cada categoría y con ellas la media general. El resultado que se muestra al usuario es el siguiente:
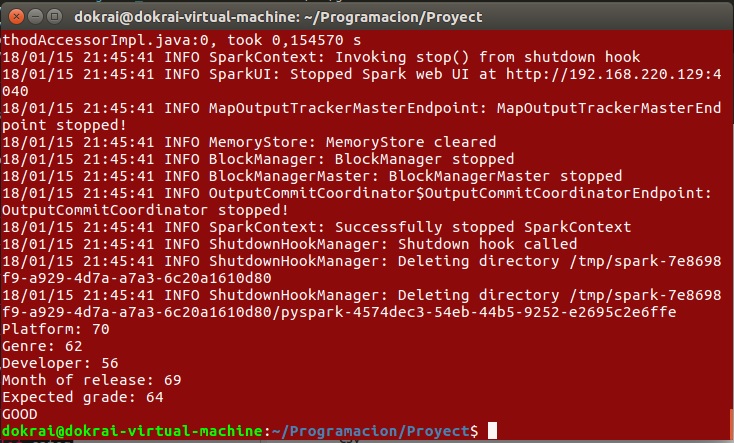
La segunda opción es casi idéntica solo que, en vez de predecir la nota, predice las ventas que se van a obtener. La petición de datos al usuario y el procesamiento de estos es igual que en el caso anterior pero cambiando la columna utilizada para calcular la media. El resultado que se muestra al usuario es muy similar al anterior:
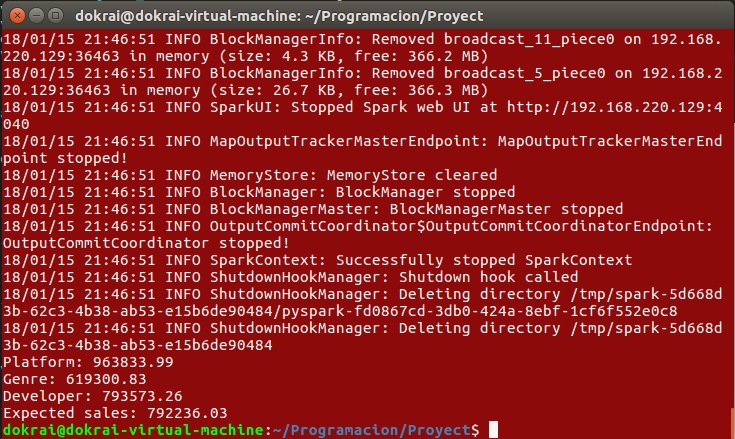
La tercera es un mecanismo de consulta que permite al usuario buscar la media tanto de notas como de ventas de cualquiera de las categorías disponibles. Se le pedirá al usuario primero que indique si quiere conocer la media de las notas o de las ventas y segundo qué categoría quiere consultar. Por último se le pedirá que inserte un valor y, si ese valor se encuentra entre nuestros datos, se le mostrará la media pedida. Lo que se le muestra al usuario es lo siguiente:
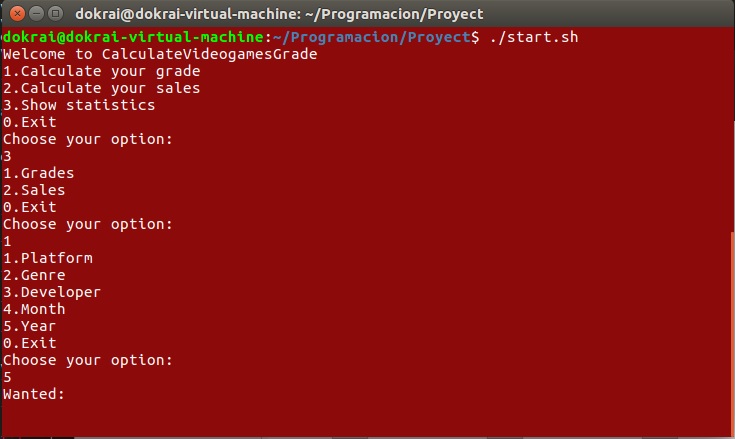
Rendimiento
El programa recorre los CSVs enteros una vez para crear los RDDs y otra para cada categoría para filtrar los datos que nos interesan. Tras esto, las medias se realizan sobre RDDs mucho más pequeños lo que acelera un poco el proceso.
Por ahora los datos, a pesar de ser numerosos, no son lo suficientemente grandes para que el programa se relentice debido al recorrido de los RDDs para cada categoría. Actualmente se tardan 13,85 segundos en ejecutar una predicción de nota y 9,97 para una predicción de ventas. La predicción de ventas es ligeramente más rápida ya que sólo utiliza el CSV de Metacritic. La situación podría emporar cuando el número de datos aumente mucho, ya sea por los años o por incluir nuevos medios de los que obtener datos (otras revistas, plataformas…). Podría solventarse utilizando más nodos que paralelicen el filtrado de información.
Qué hemos aprendido
Durante la realización de este proyecto hemos adquirido multitud de conocimientos nuevos, entre ellos, los más destacados son:
- Como nuestra aplicación está hecha en Python, desplegado sobre AWS, hemos aprendido a desarrollar aplicaciones en Python y a gestionar un servidor en AWS, así como Spark y MapReduce.
- Al utilizar Github como nuestro sistema de control de versiones hemos aprendido a utilizar Git y el cliente de escritorio de Github.
- Hemos aprendido a utilizar Github Pages para el desarrollo de esta página web.
- Hemos trabajado con data science y estadística para tratar los datos y obtener toda la información.
Hoja de ruta
Dentro de las acciones para ampliar el sistema, consideramos las siguientes:
-
Experiencia de usuario
1.1. Interfaz de usuario
Para mejorar la usabilidad de la aplicación se considera realizar una página web mediante la cual el usuario pueda relacionarse con el motor predictivo de forma mas amigable, además de mostrar información sobre los datos usados para el análisis.1.2. API
Desarrollar una API que permita acceder al motor de predicción de notas de videojuegos permite que la funcionalidad desarrollada por nuestro proyecto sea utilizada en multitud de aplicaciones y desarrollos de terceros.
Adicionalmente realizar una API que tenga acceso al motor de predicción, permitiria utilizar nuestros algoritmos con una gran variedad de fuentes de datos distintas. Lo que peremitiria una expansión del alcance inicial de nuestro proyecto, además de una significativa cantidad de datos de pruebas para mejoras los algoritmos. -
Ampliación de alcance
2.1. Mostrar estadísticas
Añadir una visualización para las estadísticas de los datos procesados.2.2. Fuentes de datos
Para aumentar la precisión de la aplicación se requiere un mayor número de datos, tanto en forma de nuevas fuentes de calificación como en forma de nuevas entradas a los conjuntos de datos ya disponibles.2.3. Obtención de datos
Para ampliar y actualizar los datos disponibles, el desarrollo de una araña que indexe la información de forma automática, las páginas web de los medios especializados que sean objetivo de nuestra aplicación, consiguiendo una información más actualizada y amplia con un menor esfuerzo de desarrollo. -
Algoritmia
Para aumentar la precisión del análisis se estudiarían las distrubuciones de datos de acuerdo a los modelos estadísticos y se aplicarían los modelos de distribución obtener unos resultados mas afinados.
Conclusiones
Lo más interesante del proyecto ha sido realizar una pequeña aplicacion funcional desde el principio sin tener referencias en las que apoyarse. Hemos tenido que investigar cómo desarrollar el código necesario para satisfacer la funcionalidad de nuestra aplicación en un lenguaje del que ninguno tenía conocimiento previo. Además hemos podido aplicar conocimientos adquiridos en otras asignaturas para realizar la predicción de nota.
Las principales frustraciones han sido enfrentarnos con un lenguaje desconocido a una funcionalidad compleja, lo que nos ha costado más tiempo del estimado, para otras plataformas. Este retraso nos ha supuesto una disminución en el tiempo disponible para el desarrollo de los modelos estadísticos que teníamos planeados para el cálculo de la nota.
Si volviésemos a empezar el proyecto desde el principio nos enfrentaríamos a él con otras expectativas y una estimación de tiempos más realista, ya que ha sido lo que más nos ha condicionado a la hora de realizarlo.
Con todo esto, podemos decir que ha sido una experiencia enriquecedora y que nos ha ayudado a tener un mejor conocimiento sobre el funcionamiento de las aplicaciones con Big Data y Data Science y hemos sido capaces de crear una aplicación funcional por nuestros propios medios.
Nosotros
Proyecto realizado por: